GITHUB WEBSCRAPER
About
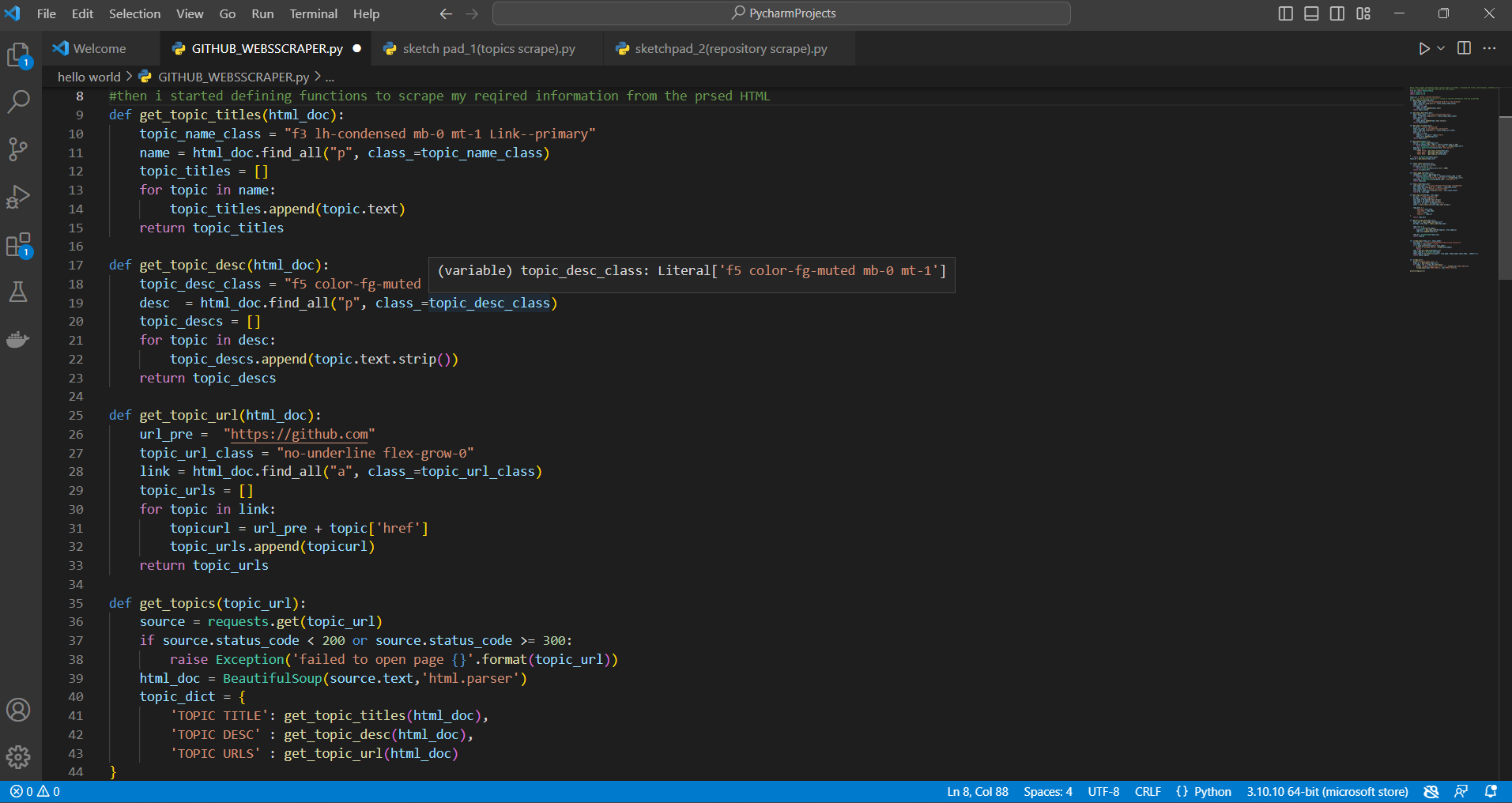
In this project, I scraped GitHub topics using Python and BeautifulSoup. Let me walk you through the details of this project.
The main objective of this project was to extract information about popular GitHub topics, such as the topic title, description, and the repositories associated with each topic. The goal was to create a dataset that could be used to analyze the most popular GitHub topics and repositories.
I used Python and the BeautifulSoup library to scrape the data. Pandas was used to organize and store the data in a dataframe. I also used requests and os libraries for web requests and file management.
To begin the project, I started by identifying the URL for GitHub topics. Then, I wrote functions to extract information about the topic titles, description, and associated URLs using BeautifulSoup. Next, I wrote functions to extract information about the repositories associated with each topic, including the repository name, the number of stars, the URL for the repository, and the username of the repository owner.
After extracting the necessary data, I created a dataframe containing the topic title, description, and associated URLs for each topic. I then wrote a function to scrape the repository information for each topic and stored the resulting data in separate excel files for each topic. The data can be used to analyze popular GitHub topics and repositories.
This project was a great opportunity for me to gain experience in web scraping using Python and BeautifulSoup. It was interesting to see the variety of popular topics on GitHub and the repositories associated with each topic.
You can check my GitHub page for the scraped data, and also for the code and more description.